Belangrijke updates en verbeteringen voor MyHeritage DNA Matching

We zijn verheugd om belangrijke updates en verbeteringen van DNA Matching aan te kondigen die vandaag voor al onze gebruikers worden uitgerold. Iedereen die een MyHeritage DNA-test heeft laten uitvoeren en iedereen die DNA-gegevens van een ander bedrijf heeft geüpload, ontvangt vanaf nu nauwkeurigere DNA-matches, meer matches (ongeveer tien keer zoveel), minder fout-positieve resultaten, specifiekere en nauwkeurigere verwantschapsschattingen en aanwijzingen om onzekere DNA-matches gericht te onderzoeken. We hebben ook de chromosomenbrowser toegevoegd, waar u al zo lang om had gevraagd. Zie de beschrijving hieronder.
Ons Science Team heeft de afgelopen maanden hard aan deze verbeteringen gewerkt. Het heeft veel tijd en moeite gekost, omdat we de wetenschap wilden perfectioneren en onze gebruikers optimale resultaten willen leveren.
Wat is DNA-matching?
MyHeritage DNA heeft momenteel meer dan een miljoen mensen in de DNA-database. 1.075.000.000 mensen, om precies te zijn. DNA-matching vergelijkt DNA-gegevens in de database met elkaar om verwanten te vinden, mensen die DNA-segmenten met elkaar delen, en om uit te leggen hoe deze individuen met elkaar verwant zijn. De aanwezigheid van gedeelde DNA-segmenten tussen twee mensen kan wijzen op een bloedverwantschap, wat betekent dat de gedeelde segmenten zijn overgeërfd van een gemeenschappelijke voorouder. Als de gedeelde segmenten talrijk en groot zijn, is een bloedverwantschap zekerder. Aan de andere kant, als de gedeelde segmenten klein in aantal en omvang zijn, kan het ook een kwestie van toeval zijn en kan er helemaal geen bloedverwantschap bestaan. Als er een match wordt gerapporteerd die helemaal geen familielid is, dan is er sprake van een fout-positief resultaat.
Als u een MyHeritage DNA-test hebt laten uitvoeren of uw DNA-gegevens naar MyHeritage hebt geüpload, dan hebt u een lijst met uw DNA Matches ontvangen. De matches worden dagelijks bijgewerkt en gebruikers worden wekelijks per e-mail geïnformeerd over de beste nieuwe matches die ze die week hebben ontvangen. Met “beste” bedoelen we de matches met de grootste hoeveelheid gedeeld DNA, wat duidt op een nauwere relatie. De lijst met DNA-matches toont individuen die DNA-segmenten met u delen, de hoeveelheid en het percentage DNA dat u deelt, het aantal DNA-segmenten dat u deelt en de grootte van het grootste gedeelde segment. MyHeritage schat ook de relatie in door het aantal en de grootte van de gedeelde DNA-segmenten in elk match te analyseren en deze te vergelijken met een referentiepool van honderdduizenden andere matches met bekende relaties in stambomen die door middel van DNA zijn bevestigd. De pagina DNA Match Review biedt aanknopingspunten om uw herkomst terug te voeren naar uw gemeenschappelijke voorouder.
Vanaf vandaag zullen gebruikers die al eerder DNA-matches hebben ontvangen, gewijzigde en verbeterde matches zien. Er zullen vele nieuwe matches verschijnen. Fout-positieve resultaten die u eerder hebt ontvangen, zullen verdwenen zijn. De parameters van veel matches zullen zijn veranderd (bijvoorbeeld de hoeveelheid gedeeld DNA) en de waarden zullen nauwkeuriger zijn. Gebruikers die nog geen matches hebben ontvangen, zullen vanaf dag één matches van een betere kwaliteit ontvangen.
Hoe werkt DNA-matching?

Schematische voorstelling van het proces om DNA-matches te bepalen.
Laten we beginnen met een snel overzicht van hoe DNA-matching werkt. Dan gaan we dieper in op de verbeteringen die we in de verschillende stadia van het proces hebben aangebracht.
Het proces begint wanneer u een DNA-test neemt en uw monster naar ons laboratorium stuurt. In het lab lezen we uw DNA uit en produceren we een gegevensbestand met informatie. We lezen niet elk deel van uw DNA uit, want dan zouden we ongeveer 3 miljard punten moeten verwerken. Dit is een dure methode genaamd “whole genome sequencing” die momenteel alleen is weggelegd voor specifieke klinische toepassingen en wetenschappelijk onderzoek. In plaats daarvan richten we ons op het uitlezen van ongeveer 700.000 gebieden in uw DNA waarvan bekend is dat ze variëren tussen individuen, dit zijn de zogeheten “single nucleotide polymorphisms”, of SNP’s (in het Engels uitgesproken als “snips”). Deze methode wordt genotypering genoemd en produceert een gegevensbestand met elke SNP die we uitlezen, zijn positie in uw DNA en de twee genotypen die we daar hebben gevonden (dat wil zeggen de A, T, G of C die u van elke ouder hebt overgeërfd). Als u DNA-gegevens van een ander bedrijf hebt geüpload, ontvangen wij het gegevensbestand met dezelfde informatie.
Vervolgens passen we imputatie toe om af te leiden welke SNP’s we niet hebben uitgelezen. De imputatie van DNA is vergelijkbaar met het lezen van een zin waarin sommige letters ontbreken. De kans is groot dat je de ontbrekende letters uit de rest van de zin kunt opmaken. Niet alle DNA-testers lezen dezelfde SNP’s uit. Om DNA-matches te vinden voor personen die verschillende DNA-dienstverleners hebben gebruikt, is het belangrijk om de SNP’s af te leiden die niet werden uitgelezen, voordat de resultaten werden vergeleken. Sommige mensen twijfelen aan de nauwkeurigheid van imputatie. We hebben echter vastgesteld dat deze methode zeer nauwkeurig is wanneer ze op de juiste wijze wordt gebruikt, en in sommige situaties is het gebruik ervan onvermijdelijk.
Na de imputatie volgt het faseren. In elk chromosomenpaar ontvangt ieder mens één chromosoom van zijn moeder en één van zijn vader. De genotyperingstechnologie die uw DNA-monster uitleest, bepaalt voor elke SNP welke genotypen u van uw ouders hebt overgeërfd maar deze technologie vertelt ons niet welke varianten u van een bepaalde ouder hebt overgeërfd. Dit lossen we op door te faseren. Dit bundelt alle varianten die u van uw moeder hebt overgeërfd en alle varianten die u van uw vader hebt overgeërfd.
De volgende stap is het uitvoeren van de daadwerkelijke matching en het onderling vergelijken van alle DNA-resultaten in de database waarvoor de eigenaars matching hebben toegestaan. Dit doen we met een uiterst schaalbaar systeem dat Hadoop heet en waarmee we zeer efficiënt enorme hoeveelheden gegevens op meerdere computers tegelijk kunnen verwerken. Matching identificeert de gedeelde segmenten tussen iedere combinatie van twee testresultaten, waaruit (indien aanwezig) de relatie tussen twee personen kan worden afgeleid. Aangrenzende gedeelde segmenten worden met elkaar gekoppeld als ze als aaneengesloten worden beschouwd.
Ten slotte gebruiken we geavanceerde statistische algoritmen, classificators genaamd, om de DNA-matches te evalueren en fout-positieve resultaten af te wijzen, om het betrouwbaarheidsniveau te bepalen van de matches die niet zijn verworpen en om voor iedere match de verwantschapsrelatie te bepalen. Zo maken we uw lijst met DNA-matches.
Hoe hebben we DNA-matching verbeterd?
We hebben de nauwkeurigheid van de imputatie aanzienlijk verbeterd door meer dan tien keer zoveel referentiegenomen te gebruiken. Een persoon die tien keer zoveel boeken leest, wordt beter en nauwkeuriger bij het herleiden van ontbrekende letters. Onze imputatie van SNP’s is aanzienlijk beter en nauwkeuriger geworden door de grotere verzameling referentiegenomen.
We hebben het faseren gecorrigeerd. Voorheen slopen er tijdens het faseren wel eens fouten in het DNA-matchingproces. Die fouten veroorzaakten fout-positieve resultaten, omdat het belang van gedeelde segmenten met zeer verre verwanten werd overschat, terwijl het belang van gedeelde segmenten met naaste verwanten soms werd ondergewaardeerd. We gebruiken nu een beter algoritme dat deze faseringsfouten oplost.
In de matchingfase hebben we de drempelwaarde voor genotyperingsfouten opnieuw gekalibreerd. De technologie waarmee uw DNA-monster wordt uitgelezen maakt af en toe fouten. Dit worden genotyperingsfouten genoemd. Als er een genotyperingsfout optreedt in het midden van wat een gemeenschappelijk segment tussen DNA-matches zou moeten zijn, dan zal dat segment niet identiek lijken en kan het worden opgesplitst in twee kleinere matchende segmenten. We hebben de drempelwaarde opnieuw gekalibreerd voor situaties waarin we kleine afwijkingen tussen verder matchende segmenten vinden. We negeren in die gevallen de afwijkingen en behandelen de gedeelde segmenten als identiek, ondanks kleine stukjes die niet matchen. Deze methode compenseert onvermijdelijke genotyperingsfouten. Als we afwijkende gedeelten negeren die te groot zijn, dan gaan we er per ongeluk van uit dat een segment gedeeld wordt, terwijl dat niet het geval is. Als we niet af en toe genotyperingsfouten negeren, missen we hoogstwaarschijnlijk werkelijke DNA-matches. De nieuwe kalibratie is strenger dan de voorgaande, waardoor er minder fout-positieve resultaten door zullen glippen.
Matches met verre verwanten zijn nu toegestaan. Nadat we de nauwkeurigheid van de matches hadden verhoogd en de bovenstaande parameters hadden gekalibreerd, voelden we ons zeker genoeg om u ook matches met verre verwanten te laten zien. Vroeger was het minimum voor gedeeld DNA voor een match 12 cM en nu is het minimum 8 cM. Dit resulteerde samen met de andere verbeteringen in een vertienvoudiging van het aantal DNA-matches dat onze gebruikers nu zullen ontvangen.
Deze matches zullen automatisch verschijnen voor iedereen die al een MyHeritage DNA-test heeft laten uitvoeren en voor iedereen die zijn DNA in het verleden naar MyHeritage heeft geüpload of dat in de toekomst zal doen.
Betere koppeling tussen aangrenzende segmenten. Naast het compenseren van genotyperingsfouten binnen segmenten is het noodzakelijk om de resterende faseringsfouten tussen segmenten te compenseren. Bijvoorbeeld, als we het geslachtschromosoom buiten beschouwing laten, zouden een moeder en haar dochter in een autosomale DNA-test 22 matchende segmenten moeten hebben: van elk chromosomenpaar van de dochter is één heel chromosoom overgeërfd van haar moeder en dus zou elk van de 22 autosomale chromosomen in één lang matchend segment moeten voorkomen. Echter, als gevolg van faseringsfouten worden soms kleine delen van het chromosoom dat van de moeder is overgeërfd, door de computer verwisseld met de parallelle delen die van de vader zijn overgeërfd. Dat is dus geen biologische fout maar een technische. We hebben deze fout gecorrigeerd door de afstand te vergroten die we bij het koppelen van mogelijk aangrenzende segmenten moeten overbruggen. Om geen nieuwe fouten te introduceren moest dat proces heel precies worden gekalibreerd.
De laatste stap bij DNA-matching is het filteren van fout-positieve resultaten en het inschatten van de specifieke verwantschap tussen twee individuen met gedeelde DNA-segmenten. Omdat velen van ons afstammen van dezelfde voorvaderen, hebben we vaak kleine DNA-segmenten gemeen met mensen die we niet echt als onze familie beschouwen. We hebben naar een methode gezocht om dergelijke matches uit te filteren, omdat die voor genealogen alleen maar frustrerend zijn. Hiertoe meten we fout-positieve resultaten intern door te kijken naar trio’s. Onder trio’s verstaan we een groepje van een kind, een moeder en een vader die alle drie zijn getest met MyHeritage DNA-kits en resultaten hebben ontvangen die de verwantschap tussen beide ouders en het kind bevestigen. Elke match die een kind heeft met een andere persoon die noch met de vader noch met de moeder matcht, wordt ervan verdacht fout-positief te zijn. We noemen dat een child-only match. We meten het percentage child-only matches onder alle matches voor kinderen in bekende trio’s op MyHeritage. Deze waarde noemen we “percentage of suspected false positives indicated by child-only matches”, of in goed Nederlands: “percentage vermoedelijke fout-positieve resultaten op basis van personen die met een kind matchen zonder ook met de vader of moeder van dat kind te matchen”. Het is ons gelukt om deze waarde terug te brengen naar 16 tot 20%, een goed resultaat waarmee we andere DNA-testers evenaren of overtreffen. Door onze verbeterde classificatiealgoritmen hebben we ons percentage fout-positieve resultaten radicaal kunnen verlagen.
Maar daar hebben we het niet bij gelaten. We wilden een methode bedenken waarmee u uw genealogisch onderzoek zo effectief mogelijk kunt uitvoeren. Hiervoor gebruikten we onze statistische algoritmen. We deelden de matches in in: zeer betrouwbaar, redelijk betrouwbaar en niet betrouwbaar. Matches die redelijk of niet betrouwbaar zijn, worden op de website als zodanig aangeduid. Dit zijn DNA-matches die u sceptisch moet behandelen, omdat er een kans bestaat dat het fout-positieve resultaten zijn. Dergelijke matches hebben doorgaans weinig en zeer kleine gedeelde DNA-segmenten. Met deze aanwijzingen kunt u uw tijd optimaal benutten. Onderzoek eerst de zeer betrouwbare matches en doorzoek, als u zin hebt in een uitdaging, daarna pas de minder betrouwbare matches op zoek naar verborgen schatten. Merk op dat redelijk betrouwbare en niet betrouwbare matches niet zijn opgenomen in de wekelijkse e-mailmeldingen over nieuwe matches.
De nieuwe classificators werken zo goed dat het percentage child-only matches dat niet wordt gekenmerkt als niet of redelijk betrouwbaar tot minder dan 5% is gedaald. Met andere woorden: als u een zeer betrouwbare DNA-match op MyHeritage bekijkt, kunt u er nu bijna zeker van zijn dat u uw tijd niet verspilt met een fout-positief resultaat. Als u een match te zien krijgt die door ons is ingeschat als een achterneef of -nicht of een nauwere verwant, dan kunt u er zeker van zijn dat u zoveel DNA met die persoon deelt dat u wel verwant moet zijn.
De nauwkeurigheid van een verwantschapsschatting voor een DNA-match wordt gemeten met behulp van twee parameters die we recall (sensitiviteit) en precision (specificiteit) noemen. Perfecte nauwkeurigheid betekent dat we een gebruiker keer op keer de juiste verwantschap met een DNA-match vertellen (sensitiviteit) en dat we daarbij geen slag om de arm houden door meerdere familiebanden te suggereren (specificiteit). Bijvoorbeeld, als twee mensen elkaars broer of zus zijn, zal een perfect algoritme suggereren dat ze broers of zussen zijn, en niets anders. Een perfect algoritme maakt niet de inschatting dat het of broers en zussen of neven en nichten kunnen zijn. (Biologisch gezien is dit theoretische perfecte algoritme echter niet mogelijk, vanwege de manier waarop DNA wordt overgeërfd.) MyHeritage suggereert nu in 93% van de gevallen de juiste verwantschap voor verre verwanten als achternichten en -neven, en dat is werkelijk niet gemakkelijk. Voor naaste verwanten is de nauwkeurigheid veel hoger: bijna 100%. Bovendien suggereren we hoogstens twee of drie mogelijke verwantschappen voor DNA-matches met neven en nichten of mensen die nauwer verwant zijn. Voor verre neven en nichten laten we gemiddeld tot vijf mogelijke relaties zien, bijvoorbeeld of iemand een nicht van een van de ouders is of een achterachterneef of -nicht. De sensitiviteit en specificiteit van de verwantschapsschattingen van MyHeritage zijn nu veel beter dan voorheen.
We hebben de hoge kwaliteit van ons nieuwe DNA-matchingalgoritme gevalideerd door nieuwe lijsten met DNA-matches te vergelijken met die van andere DNA-bedrijven en de resultaten komen goed overeen.
Sommige endogame bevolkingsgroepen, zoals Asjkenazische Joden, vormen een unieke uitdaging bij het matchen van DNA. Omdat in dergelijke populaties steeds opnieuw binnen de eigen groep werd getrouwd, hebben niet-genetisch verwante personen binnen deze groep meer gedeeld DNA dan normaal valt te verwachten. MyHeritage heeft met behulp van machine learning een extra classificatiealgoritme getraind om Asjkenazische relaties te classificeren met een hogere verfijningsgraad dan andere DNA-testers. We gebruikten deze classificator om de fout-positieve resultaten voor Asjkenazische Joden beter te verwerpen en brachten de groep daarmee op hetzelfde niveau van fout-positieven als de algemene bevolking.
Wat betekenen deze verbeteringen voor MyHeritage DNA-gebruikers?
U ontvangt nu:
- Nauwkeurigere DNA-matches
- Ongeveer tien keer zoveel DNA-matches
- Preciezere en nauwkeurigere verwantschapsschattingen
- Aanwijzingen over de betrouwbaarheid van de DNA-matches om uw onderzoek te vergemakkelijken
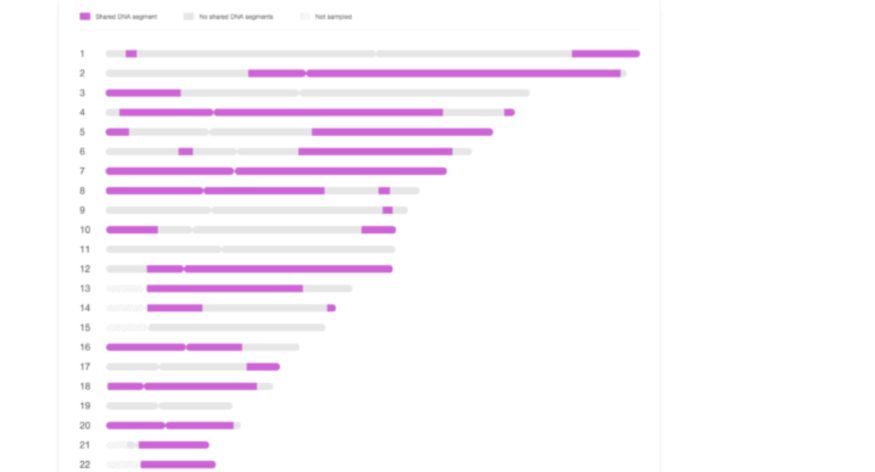
Chromosomenbrowser
Naast de verbeteringen in nauwkeurigheid hebben we ook nieuwe functies toegevoegd om het gebruik van DNA Matches te verbeteren. De eerste, op velerlei verzoek, is een chromosomenbrowser voor gedeelde DNA-matches. Het is toegevoegd aan pagina DNA Match Review.

Een chromosomenbrowser biedt een schematische weergave van iemands chromosomen om DNA-segmenten te visualiseren. Veel van onze gebruikers hebben om een chromosomenbrowser gevraagd en we weten dat dit een belangrijk hulpmiddel voor genealogen is. Daarom hebben we beloofd dat we er een zouden ontwikkelen en nu doen we die belofte gestand. De nieuwe chromosomenbrowser van MyHeritage is een eerste release. We zullen de browser binnenkort verder verbeteren. Hij is bedoeld om het DNA te bekijken dat u met DNA-matches deelt. Het is een gratis functie die kan worden gebruikt door alle gebruikers van MyHeritage die de DNA-test hebben laten uitvoeren of DNA-gegevens hebben geüpload. De segmenten die u met een DNA-match deelt worden in het paars weergegeven. Als u uw muisaanwijzer over een gedeeld segment beweegt, kunt u de genomische positie, de grootte en het aantal SNP’s voor het gedeelde segment bekijken. Grijze segmenten worden niet gedeeld met de DNA-match en gearceerde secties zijn niet geanalyseerd omdat ze onvoldoende SNP’s bevatten. Hoewel we nooit zouden toestaan dat een andere gebruiker uw ruwe DNA-gegevens downloadt, moeten we u toch op het volgende attent maken. Een andere gebruiker die een segment met u deelt en de positie en grootte daarvan kan bekijken, kan de genotypen die u in dat specifieke segment in uw DNA bezit, afleiden door uw gegevens met zijn of haar eigen gegevens te combineren. Gebruikers die liever voorkomen dat andere gebruikers die met hun DNA matchen de details van gedeelde segmenten kunnen bekijken, kunnen zich voor deze functie afmelden door gebruik te maken van een nieuwe privacyinstelling die we speciaal daarvoor hebben toegevoegd.
De chromosomenbrowser biedt ook de mogelijkheid om gegevens over gedeelde segmenten te downloaden. Daarvoor gebruikt u het menu “Geavanceerde opties” in de rechterbovenhoek van de chromosomenbrowser. Gevorderde gebruikers kunnen deze optie gebruiken om gegevens over de gedeelde segmenten te downloaden en in andere tools of chromosomenbrowsers te bekijken. Binnenkort komen er nog meer functies bij, zoals de mogelijkheid om de gedeelde segmenten van drie of meer DNA-matches tegelijk in de chromosomenbrowser te bekijken. Het gelijktijdig bekijken van de gedeelde segmenten van meerdere DNA-matches helpt u om de gedeelde voorouder te achterhalen, die het segment heeft doorgegeven aan alle DNA-matches die het delen en vervolgens te ontdekken hoe u allen verwant bent. We zijn ook van plan om snel de mogelijkheid toe te voegen om de gedeelde segmenten die in de chromosomenbrowser worden getoond af te drukken.
Na enige oefening zullen onze gebruikers zeker in staat zijn om de nieuwe chromosomenbrowser te gebruiken om specifieke segmenten te identificeren in hun eigen DNA en dat van hun voorouder en daardoor beter inzicht te krijgen in hun DNA-matches en de verwantschapsbanden tussen deze DNA-matches. We hopen dat dit onze gebruikers zal helpen om vastgelopen onderzoek vlot te trekken, hun voorouders te traceren en te begrijpen hoe ze verwant zijn met familieleden die ze door middel van DNA-matches hebben gevonden.
Facelift en gemakkelijker navigeren
Als onderdeel van deze update hebben we kleine wijzigingen aangebracht in de gebruikersinterface van DNA Matches, voor meer uniformiteit met de andere DNA-schermen. De meeste van deze veranderingen zijn klein en nauwelijks waarneembaar, zoals paarse in plaats van oranje knoppen op de lijst met DNA-matches. Een wezenlijke verbetering is echter dat op de pagina met de lijst met DNA-matches de DNA-test die u bekijkt ook boven de gegevens te zien blijft als u naar beneden scrolt. Daardoor weet u op ieder moment naar wiens matches u kijkt.

Werk in uitvoering
Ons werk is nooit af. Het matchen van DNA is een taak zonder einde, een taak die we ook in de toekomst steeds beter zullen uitvoeren. De groeiende omvang van onze DNA-database, en de toegenomen verwevenheid tussen de DNA-tests en de stambomen bieden ons steeds meer mogelijkheden om onze DNA-matchingalgoritmen te optimaliseren en we zijn van plan om dit regelmatig te doen en de nauwkeurigheid verder te verbeteren.
Voor wat betreft de DNA-gegevens van andere testbedrijven die naar MyHeritage worden geüpload, we ondersteunen nog steeds niet de tests die zijn uitgevoerd met behulp van de Illumina GSA-chip. Hieronder vallen de testkits van 23andMe (recente V5-versie) en Living DNA. In ons lab lukt het al om DNA-gegevens van GSA-chips te verwerken maar de resultaten zijn nog steeds niet perfect, dus hebben we besloten om ze nog niet in deze release mee te nemen. GSA-ondersteuning zal in de komende maanden worden toegevoegd.
Etniciteitsschattingen staan los van DNA Matching en de hier beschreven verbeteringen zijn niet van invloed op de etniciteitsschattingen. Er staat in de komende maanden ook een update voor de etniciteitsrapporten op stapel. Blijf op de hoogte!
Volgende stappen
Bestel een MyHeritage DNA-testkit om van al deze nieuwe functies en verbeteringen te profiteren, als u dat niet al heeft gedaan. Als u uzelf al hebt getest, overweeg dan om DNA-testkits voor uw familieleden te kopen, met name voor oudere familieleden. Dit vergroot uw kans om verwanten te vinden en biedt u de mogelijkheid om driehoeksmethoden toe te passen. Bijvoorbeeld, als u een neef van uw moeder of vader laat testen, dan kunt u matches met nieuwe verwanten die u al hebt en die ook met die neef worden gedeeld via een driehoeksmethode koppelen met een gemeenschappelijke voorouder, via een pad naar een recentere voorouder in uw stamboom die u met die neef deelt. De nieuwe chromosomenbrowser zal van pas komen om inzicht in dergelijke matches te krijgen. Dus als er een bepaalde tak in uw stamboom is waarin u het meest bent geïnteresseerd, koop dan DNA-testkits voor oudere verwanten van uzelf in die tak.
Als u uw DNA al ergens anders hebt laten testen, upload uw DNA-gegevens dan naar MyHeritage. MyHeritage is de enige van de drie grote DNA-testbedrijven waar u uw gegevens kunt uploaden. Profiteer hiervan zolang het nog kosteloos is en ontvang gratis DNA-matches en gratis etniciteitsschattingen voor uw bestaande gegevens. MyHeritage heeft een omvangrijke DNA-database van meer dan een miljoen mensen, van wie de meesten zich bij MyHeritage hebben laten testen, dus waar wacht u nog op? U ontvangt in hooguit twee dagen uw resultaten.
Als u al meer dan één DNA-test op MyHeritage beheert, neem dan even de tijd om te controleren of alle tests aan de juiste personen zijn toegewezen. Indien nodig kunt u verkeerde toewijzingen corrigeren op de pagina “DNA-testkits beheren” die u in het menu DNA kunt openen. Gebruik de optie “Testkit aan een andere persoon toewijzen” als u een test vindt die met de verkeerde persoon is gekoppeld. Dit is noodzakelijk als de tests die u voor verschillende familieleden hebt geüpload nog steeds zijn toegewezen aan uw eigen stamboomprofiel.
Ten slotte zijn DNA-testkits op MyHeritage veel nuttiger als ze aan een stamboom zijn gekoppeld. Dat biedt u meer inzicht in uw DNA-matches, bijvoorbeeld door de aanwezigheid van Smart matches en voorouderlijke achternamen of voorouderlijke geboorteplaatsen die u en een bepaalde DNA-match delen. Als u een DNA-testkit op MyHeritage hebt maar geen stamboom of een heel kleine stamboom, is het nu een goed moment om met een stamboom te beginnen of uw bestaande stamboom uit te breiden. Het zal uw DNA-matches ten goede komen maar in de eerste plaats zal het uzelf ten goede komen.
Veel plezier,
Het MyHeritage-team